滚球app中国官网下载入口 一次三篇! 李飞飞的空间智能公司, 发论文了


裁剪|Panda
今天,由李飞飞聚集创立的空间智能公司 World Labs 在合并天发布了三篇时刻论文!
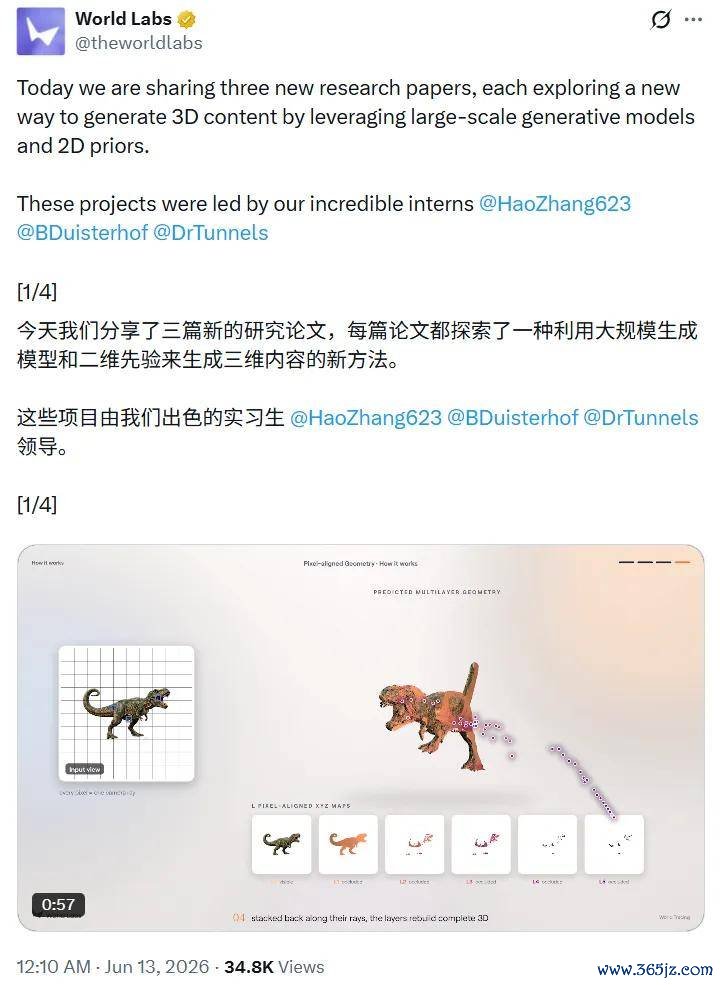
三篇论文分别由公司里面实习生主导完成,磋议主义相反,但分享合并个中枢命题:借助已在海量图片数据上检会纯属的 2D 生成模子,缩小 3D 内容生成的难度门槛。

值得夺目的是,正如 World Labs 聚集首创东说念主 Justin Johnson 所言,尽管该公司此前已有甘休展示,但这三篇论文确是该公司的首批论文(first-ever papers)。
回到这三篇论文的主题:3D 内容生成。这是一个持久以来「提及来简短、作念起来极难」的领域。
践诺天下是三维的,但检会数据绝大巨额是二维的(包括相片、视频、图像),而不是带有体积、深度和守密关系的完好空间结构。一朝转入三维,检会数据骤减,几何一致性的谨防变得指数级复杂。
畴昔数年,磋议者们一经找到了一条可行旅途:不从新检会 3D 生成模子,而是将 2D 扩散模子的雄伟先验能力迁徙到 3D 生成任务中。
World Labs 此次发布的三篇论文,分别从不同角度蔓延了这条念念路。

三项磋议的具体切入点各有侧重:
World Tracing 经管的是「从单张图像还原可见名义之外的完好三维几何」问题;
Modality Forcing 探索的是「如何让一个文生图模子同期具备深度感知和 3D 推理能力」;
Flex4DHuman 则将问题蔓延到时辰维度,尝试从经常单目视频中晋升出可合成的动态 4D 东说念主体。
值得夺目的是,就在论文发布的合并天,World Labs 聚集首创东说念主 Christoph Lassner 在酬酢媒体上文告因病将离开公司,为这场学术亮相增添了一点东说念主事变局的注脚。

底下我就来具体望望 World Labs 的首批论文。
World Tracing
让每一个像素,都指向一个完好的 3D 天下
如若你手中惟有一张相片,你能从中还原若干三维信息?
知识告诉咱们:很有限。相片仅仅践诺天下在某一时刻、某一视角下的投影,深度信息丢失,守密面后方的空间十足缺席。现时主流的单图转 3D 程序,经常濒临一个两难窘境:要么作念深度估量(精准但只可还原可见名义);要么作念生成补全(联想力丰富但甘休经常偏离原始图像的视觉细节)。
World Tracing 有运筹帷幄试图同期消解这两种颓势。

论文标题:World Tracing: Generative Pixel-Aligned Geometry Beyond the Visible
论文地址:https://arxiv.org/abs/2606.13652
名目地址:https://haoz19.github.io/world-tracing-page/
论文由 Hao Zhang 主导,团队成员包括 World Labs 聚集首创东说念主 Ben Mildenhall、Christoph Lassner、Gengshan Yang 等东说念主。

中枢念念路是:将每一个输入像素视为一条射线,沿着这条射线瞻望一组有序的三维坐标点——第 0 层是可见名义,之后各层挨次是沿该射线主义的被守密几何体。论文将这种示意称为「pixel-aligned multilayer geometry representation」(像素对皆的多层几何示意),具体罢了为一个多层 XYZ 坐标张量(multilayer XYZ stack)。
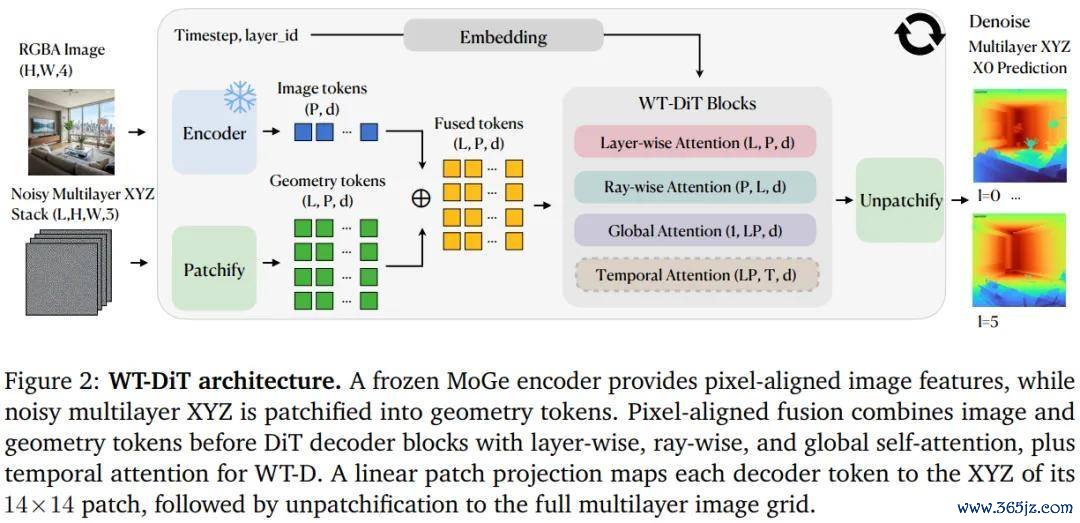
换句话说,World Tracing 给每个像素对应的不仅仅一个三维点,而是一叠有序的三维点,记载了这条视野穿越场景所经过的总共几何层:第 0 层是平直可见的名义,更深的层则逐步揭示被远景物体守密的阴私几何体。
这就像是把相机比作一支铅笔:经常深度估量只可画出物体的笼统线,而 World Tracing 试丹青出这支铅笔穿透纸张时,另一面的阵势。
瞻望这种「深度堆叠」自身是极高难度的任务,因为守密面的几何信息根柢莫得出面前图像中,模子必须依赖对践诺天下空间结构的「知识」来进行推断。
为此,磋议团队选拔了扩散模子来对这组有序深度值建模。扩散模子自然合适处理带有不细则性的漫衍式瞻望,而非给出单一细则谜底。
更重要的是,通盘瞻望过程持久对皆于原始输入图像的像素坐标。可见名义的深度被精准地「锚定」在图像信息中,而不能见部分的补全则在这个禁止框架下进行生成。这使得最终的三维重建既针织于输入图像,又具备完好的空间结构。
论文中展示的案例覆盖了静态物体、室表里场景,乃至动态天下建模。团队还发布了论文代码、名目主页和 Hugging Face 在线演示,让外界能够平直测试这套程序对苟且图像的处理效果。

关于 World Labs 这么以「空间智能」为中枢居品主义的公司来说,World Tracing 的敬爱在于:它提供了一种从单张图像动身、平直还原丰富三维结构的时刻旅途,而不需要多视角输入或不菲的三维数据标注。这与 Marble 居品「从图像生成可探索三维天下」的中枢答允高度一致。
Modality Forcing
一个模子,同期知道面容、翰墨和深度
深度估量和图像生成,在传统上是两个十足寂寞的任务,分别需要很是的数据集和寂寞检会的模子。前者需要精准的深度标注(LiDAR 扫描或双目视觉),后者依赖海量图文对。两套任务的数据领域收支悬殊——图像生成模子见过数十亿张图片,2026世界杯中国亚博app官方手机版而深度模子的检会数据量经常仅仅零头。
这种分歧称,催生了一个当然的问题:能否让一经在海量图文数据上检会纯属的文生图模子,平直学会对深度的感知?
Modality Forcing 给出了一个肯定的回报,并走得更远。
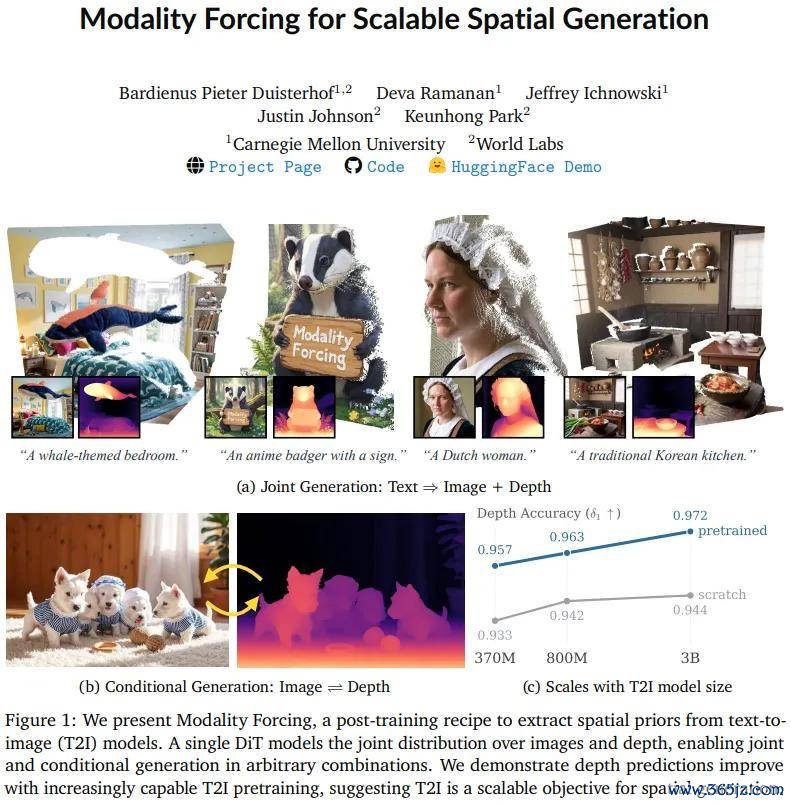
论文标题:Modality Forcing for Scalable Spatial Generation
论文地址:https://arxiv.org/abs/2606.13676
名目地址:https://modality-forcing.github.io/
这篇由 Bardienus Duisterhof 主导的 World Labs 实习磋议,中枢观念是:文生图是一种可蔓延的 3D 推理预检会目的,只须用对检会计谋,合并个模子不错在 RGBD 生成、深度估量和深度条目图像生成三项任务之间解放切换。

论文提议的程序名为「Modality Forcing」,其中枢计制是:给 RGB 和深度两种模态分别分拨寂寞的扩散噪声时辰步(per-modality noise levels)。
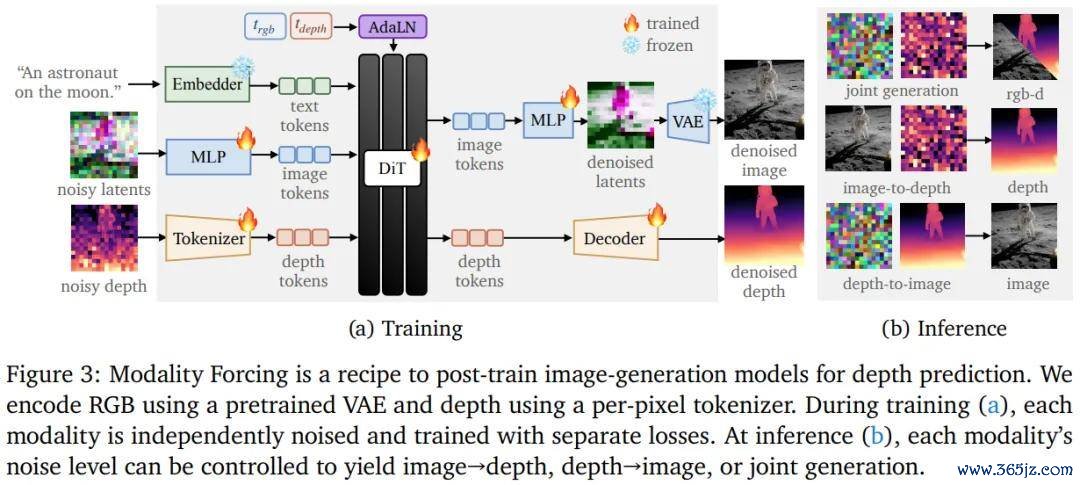
检会时,RGB 和深度各自被加入不同进程的噪声,同期给与各自寂寞的亏损监督;推理时,只需固定某一模态的噪声步为 0(即视为已知条目),对另一模态完好去噪,便可罢了图像→深度(I2D)或深度→图像(D2I)的条目生成;两者均加噪则为聚集生成。
由于深度在像素空间(而非 VAE 隐空间)中平直扩散,模子不错从仅含荒芜深度标注简直凿天下数据中学习,不再局限于依赖密集标注的合成数据集。
这种念念路的上风在于:不需要非凡引入寂寞的深度收集,也不需要为每个任务单独遐想架构分支。一个预检会的文生图模子,通过 Modality Forcing 微调之后,就具备了对场景几何的平直感知能力。
从时刻旅途来看,Modality Forcing 与连年来流行的多任务扩散模子磋议(如 Marigold、Depth Pro、Lotus 等)主义一致,但其独有之处在于对「生成」与「感知」两类任务的调解处理。深度估量经常被视为一个判别任务(给定图像,输出深度值),而文生图是一个生成任务。
Modality Forcing 的孝顺在于显露:这两种任务之间的界限比联想中浑沌得多;生成能力的蕴蓄,不错平直摇荡为感知能力的晋升,反之也是。
对 World Labs 来说,这项磋议的敬爱蔓延到居品层面:Marble 的 3D 天下生成需要对场景深度的精准知道。一个同期具备生成和感知能力的调解模子,滚球app中国官网下载入口将使 3D 天下的构建愈加自洽,幸免深度估量模块和生成模块之间的累积症结。
Flex4DHuman
从一段手机视频,「升维」出可合成的动态东说念主体
如若说前两篇论文处理的是静态或通用场景,Flex4DHuman 则将挑战聚焦于一个更具体但不异伏击的子问题:如何从一段经常的单目视频(比如手机拍摄的日常视频),重建移动态东说念主体的完好四维结构,即三维空间+时辰维度。
这个问题的难点在于「单目」两个字。多目次像系统不错通过视差平直测量三维坐标,但单目视频丢失了这种几何禁止。从单目视频重建清爽中的三维东说念主体,本体上是一个欠禁止问题:合并段视频序列,表面上对应无数种可能的三维清爽轨迹。此前的程序大多依赖优化过程,策画耗时,且难以泛化到检会集之外的姿态和外不雅。
Flex4DHuman 由 Yipeng Wang 担任名目负责东说念主,第一作家为 Jen-Hao Cheng,责任在 World Labs 实习时间完成。

论文标题:Flex4DHuman: Flexible Multi-view Video Diffusion for 4D Human Reconstruction
论文地址:https://arxiv.org/abs/2606.13655
名目地址:https://andy-cheng.github.io/Flex4DHuman/

程序以阿里巴巴的 Wan 2.1(一个 1.3B 参数的文本生成视频 DiT)为基础进行微调,中枢转变惟有一处:将原有的时空位置编码替换为一套五轴位置编码(five-axis positional encoding),在原有的空间坐标和帧序索引之外,非凡引入视角槽索引和连气儿 SE(3) 相对相机几何,使模子在夺眼力机制里面平直感知相机之间的相对位姿关系。
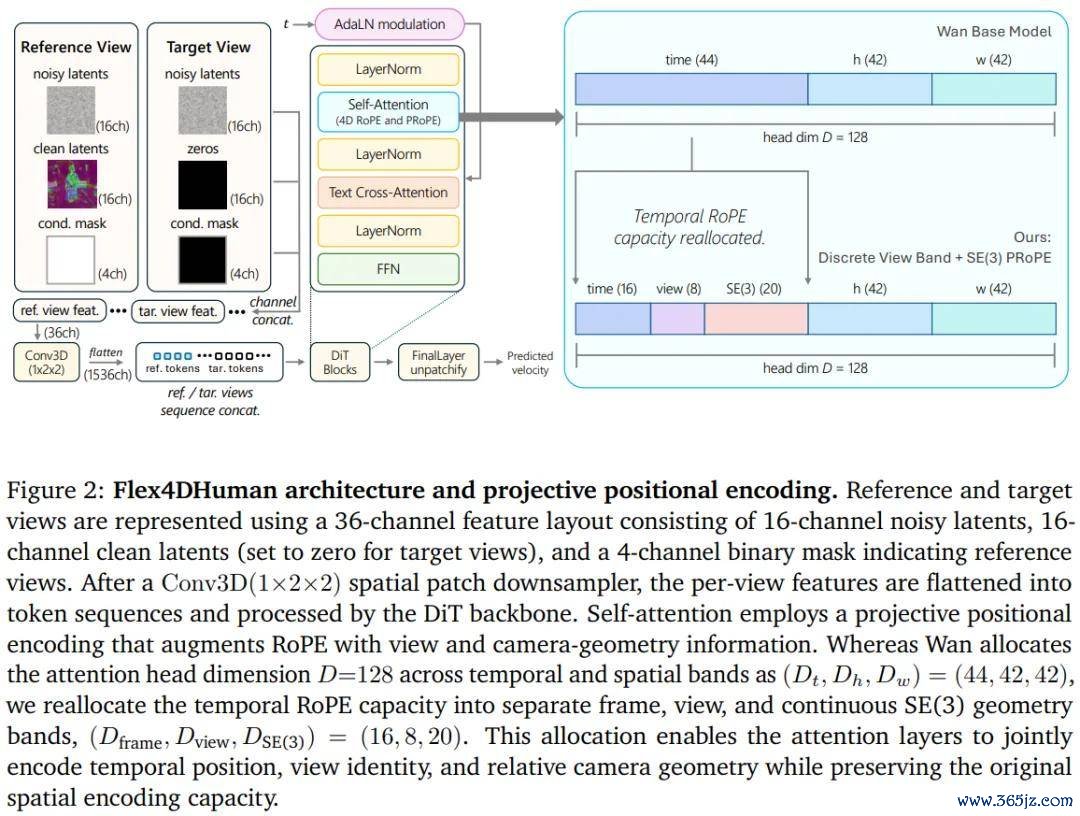
这个遐想带来了一个重要上风:不需要骨架估量(skeleton)、深度图或法线图等显式几何先验,仅凭相对相机姿态就能脱手多视角视频的同步生成。这与此前主流程序(如 Diffuman4D 依赖 SMPL 骨架、MV-Performer 依赖深度和法线渲染)形成显着对比。
给定一段单目参考视频和目的相机姿态,模子平直输出在时辰上同步、视角上一致的多视角视频序列;再将这些多视角视频送入 FreeTimeGS 重建管线,即可得到动态 4D 高斯示意(4D Gaussian Splats)。
这套历程将视频扩散模子的雄伟外不雅先验与 4D 高斯的高效渲染能力趋附起来,使得从一段舞蹈视频或行走视频动身,不错将其中的东说念主物「升维」为完好的动态 4D 钞票,再合成进苟且 3D 场景。这关于数字内容创作、诬捏制片和 AR/VR 应工具有平直价值。

论文还考证了程序超出东说念主体的泛化性:合并个模子经过少许微调后,不错履行到多物种动物的多视角生成,在跨物种零样本测试中仍保抓较强性能,标明程序的中枢遐想不依赖东说念主体特有的几何假定。
论文在 DNA-Rendering 和 ActorsHQ 两个基准上进行了评测。与不异基于单目参考视频的 Diffuman4D-mono-skeleton 比较,Flex4DHuman 在 DNA-Rendering 上 PSNR 晋升约 9.3 dB;在零样本的 ActorsHQ 测试集上,PSNR 也跨越敌手约 3.4 dB。
从更宏不雅的视角来看,Flex4DHuman 代表了「2D 视频数据赋能 3D 天下建模」这一时刻道路的一个典型样本。手机视频是东说念主类日常分娩最多的数据阵势,如若能够高效地从中提真金不怕火四维信息,将极大蔓延 3D 天下模子的检会数据开端。
联创 Christoph Lassner 文告下野
就在三篇论文发布的合并天,World Labs 聚集首创东说念主 Christoph Lassner 在 X 平台发帖,文告我方将离开公司,开启下一段旅程。

Lassner 是 World Labs 四位聚集首创东说念主之一,另外三位分别是李飞飞、Justin Johnson 和 Ben Mildenhall。他持久从事策画机视觉与策画机图形学交叉领域的磋议,专注于从 2D 图像和视频中还原可用的三维内容。
在加入 World Labs 之前,Lassner 的处事轨迹覆盖了多个行业前沿。他曾在初创公司 Bodylabs 责任,该公司后被亚马逊收购,专注于基于图像的三维东说念主体建模;在亚马逊时间,他主导建造了 Amazon Halo 智高手环的三维体型估算系统,用户仅需手机自拍,即可获取精准的三维体格模子。而后,他先后在 Meta Reality Labs Research 和 Epic Games 主抓磋议团队,深耕神经渲染和 NeRF(神经发射场)商量时刻,2022 年 Meta Connect 大会上展示的及时发射场渲染演示,恰是他场所团队的甘休之一。他还建造了 Pulsar 渲染器,一种基于球体基元的可微分渲染器,自后成为 PyTorch3D 的后端组件之一,在学术界得到庸俗愚弄。
Lassner 于 2024 年头与李飞飞等东说念主共同创立 World Labs。公司于同庚 9 月从隐身情状中走出,以约 10 亿好意思元估值完成 2.3 亿好意思元融资,投资方包括 NVIDIA、AMD、Adobe 和 Databricks 旗下风险投资机构。2026 年 2 月,World Labs 完成了由 Autodesk 领投的 10 亿好意思元新一轮融资,估值跃升至约 50 亿好意思元。
三篇论文的致谢列表中均出现了 Lassner 的名字,这意味着他在任时间积极参与了这些实习磋议名目。
关于下野的原因,Lassner 在公开声明中作念了坦诚的证实:畴昔几个月里,他履历了数起个东说念主事故,其中包括一次形成多处骨折和脑轰动的不测,面前仍在还原中。这段强制休息的时辰让他有契机再行注视我方的处境,并作念出了退出日常运营职务的决定。他同期示意,将不时以照拂人身份因循公司,并对李飞飞、Justin Johnson 和 Ben Mildenhall 在这一决定过程中予以的知道和因循抒发了感谢。
在向公司里面团队发送的信件中,Lassner 写说念,他「确信 World Labs 以及咱们正在构建的奇迹的伏击性」,公司面前所处的刚劲位置让他确信此刻是交棒的合当令机。他示意,我方下一步的策画尚不解确,但「对行将到来的事感到慷慨」。
结语
开云体育中国官网在线入口三篇论文同日亮相,对 World Labs 而言是一个值得记载的时辰节点。这家公司自 2024 年创立以来,主要以时刻博客和居品的阵势与公众碰头:Marble 天下模子的内测与公测、World API 的绽开、Spark 2.0……而此次是公司初次以 arXiv 预印本阵势负责发表学术论文。
此次的集体亮相,聚集首创东说念主 Justin Johnson 在 X 上的指摘简略最能证实其布景意涵:「3D 是一个令东说念主慷慨的领域,咱们仍在摸索正确的任务界说、问题阵势、模子架构,以及最好的蔓延方式。咱们在这里分享一些想法,由一批出色的实习生主导完成。」
口吻温煦,但主义很澄清:World Labs 正在将「空间智能」的磋议道路推向更深处,并喧阗在这一过程中与学术社隔离享我方的念念考。
文中视频连气儿:https://mp.weixin.qq.com/s/tSorVEK3cAszxBw_MKLzMQ滚球app中国官网下载入口